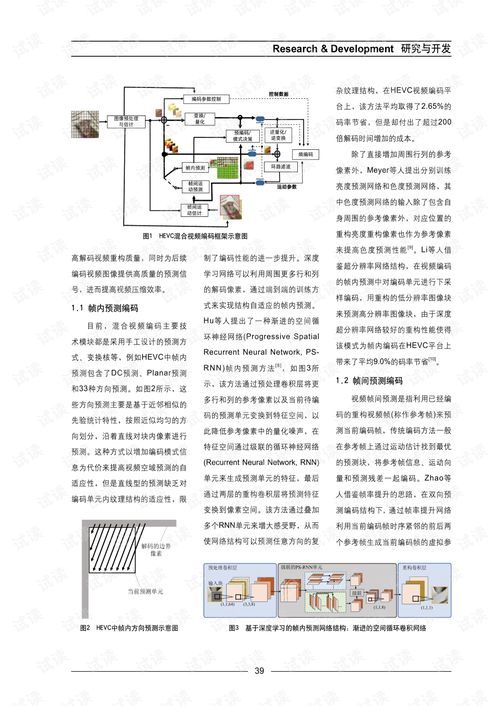
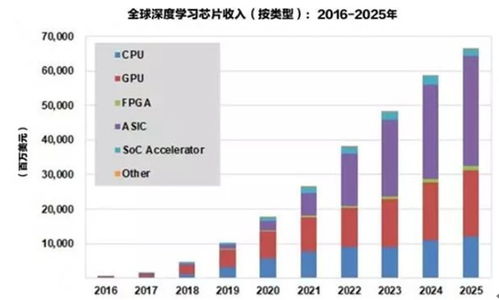
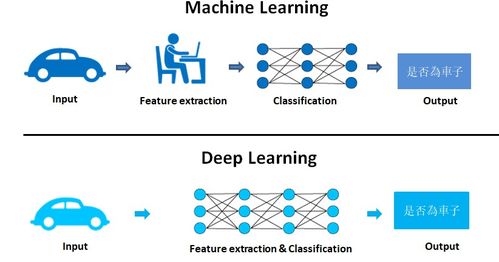
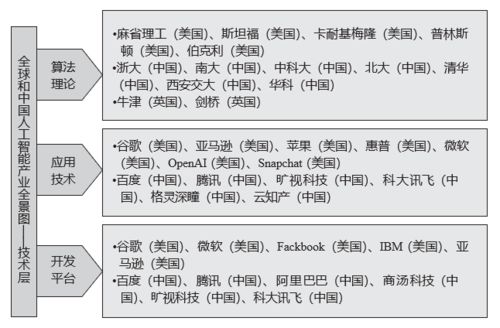
1. 引言

随着人工智能技术的不断发展,机器学习模型在各个领域得到了广泛应用。本文旨在探讨如何应用机器学习模型生成一篇文章,从数据预处理到模型应用与实现,全面介绍机器学习模型在文本生成方面的应用。
2. 机器学习模型概述
机器学习模型是一种通过学习大量数据来自动识别模式和关系的算法。在文本生成方面,常用的机器学习模型包括循环神经网络(R)、长短期记忆网络(LSTM)和变换器(Trasformer)等。这些模型能够通过学习文本数据中的语法和语义信息,自动生成符合语法规则、语义通顺的文章。
3. 数据预处理
在应用机器学习模型进行文本生成之前,需要对数据进行预处理。数据预处理包括数据清洗、分词、词向量化和编码等步骤。数据清洗主要是去除无关信息和噪声数据,分词是将文本切分成单词或词语,词向量化和编码是将单词表示成计算机可以处理的数值形式。
4. 模型训练
在数据预处理之后,需要对机器学习模型进行训练。训练模型需要选择合适的模型架构和优化器,并根据训练数据对模型进行迭代训练。在训练过程中,需要不断调整模型参数以优化模型的性能。
5. 模型评估
在模型训练完成后,需要对模型进行评估。评估指标包括准确率、召回率、F1得分和BLEU得分等。准确率是指模型预测正确的样本数占总样本数的比例,召回率是指模型预测正确的正样本数占所有正样本数的比例,F1得分是准确率和召回率的调和平均数。
6. 模型优化与调整
根据评估结果,需要对模型进行优化和调整。优化和调整的策略包括修改模型架构、调整优化器和学习率、增加数据集等。对于文本生成任务,还可以通过添加规则和手动干预来优化生成的文章质量。
7. 模型应用与实现
经过优化和调整后,可以将训练好的模型应用到实际文本生成任务中。实现步骤包括将输入数据进行预处理、使用训练好的模型进行预测、将预测结果进行后处理等。在实现过程中,还需要考虑模型运行时间和效率等问题。
8. 结论与展望
本文介绍了如何应用机器学习模型进行文本生成,从数据预处理到模型应用与实现进行了详细阐述。通过机器学习模型的应用,可以大大提高文本生成的效率和自动化水平。机器学习模型也存在一些问题,如过拟合和泛化能力不足等。未来研究方向可以包括开发更加高效和通用的文本生成算法、研究更加细致的语义理解和语言现象等。同时,随着自然语言处理技术的不断发展,可以期待更多的研究成果和技术创新将为文本生成技术的发展带来新的突破和机遇。